

Comparing Search Engine Performance: How does Cuil Stack Up to Google, Yahoo!, Live & Ask
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
This week marked the arrival of Cuil on the search engine scene. Being a huge fan of search technology and how search engines work in general, I've been spending some time playing around with the new service and thought it would be valuable to expose my data on how the classic market leaders - Google, Yahoo!, Live & Ask compare to the newcomer.
When judging the value and performance of a major web search engine, there's a number of items I consider critical to the judging process. In order, these are -- relevancy, coverage, freshness, diversity and user experience. First, let's take a quick look at the overall performance of the 5 engines, then dive deeper into the methodology used and the specific criteria.
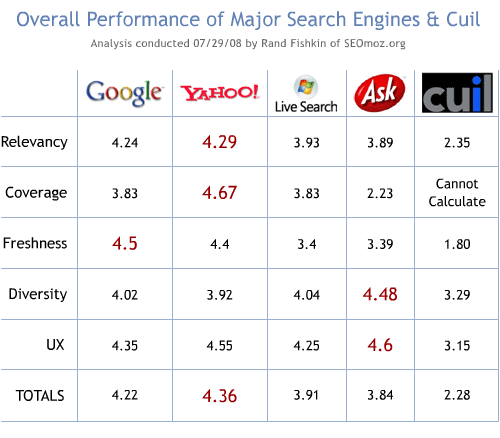
Interesting Notes from the Data:
- I'm not that surprised to see Yahoo! come out slightly ahead. Although their performance on long tail queries isn't spectacular, when you weight all of the items equally, Yahoo!'s right up there with Google. There's a reason why people haven't entirely switched over to Google, despite the far stronger "brand" they've created in search.
- Google is good across the board - again, not surprising. They're the most consistent of the engines and perform admirably in nearly every test. To my mind, despite Yahoo! eeking out a win in the numbers here, Google is still the gold standard in search.
- Ask has some clear advantages when it comes to diversity and user experience, thanks to their 3D interface, which IMO does provide some truly excellent results, particularly in the head of the demand curve.
- When it comes to index size, Yahoo! appears to have the win, but I think my test is actually a bit misleading. Although Yahoo! clearly keeps more pages on many of those domains indexed, I suspect that Google is actually both faster and broader, they simply choose to keep less in their main index (and that may actually help their relevancy results). Google's also excellent at canonicalization, an area where Yahoo! and the others all struggle in comparison.
- The biggest surprise to me? Microsoft's Live Search. I'm stunned that the quality and relevancy of Live Search is so comparatively high. I haven't done a study of this scale since 2006 or so, but the few dozen searches I run on Live each month have always produced far worse results than what I got this time around. Clearly, they're making an impact and getting better. Their biggest problem is still spam and manipulative links (which their link analysis algorithms don't seem to catch). If they fix that, I think they're on their way to top-notch relevancy.
- Cuil doesn't permit a wide variety of very standard "power" search options like site:, inurl:, intitle:, negative keywords, etc. making it fairly impossible to measure them at all on index size (though the lack of any results at all returned for terms & phrases where the other engines had hundreds or thousands speaks volumes). It also put their technical and advanced search scores in the doldrums - none of the "technorati" are likely to start using this engine, and that's an essential component of building buzz on the web Cuil's missed out on.
- Cuil was foolish to launch now. Given the buzz they had and the potential to take market share (even a fraction of a percent is worth millions), they should have had lots of people like me running lots of tests like this, showing them how clearly far behind they were from the major engines. You only get one chance to make a first impression, and theirs was spoiled. I won't predict their demise yet, but I will predict that it will be a long time before Michael Arrington or anyone in the tech or mainstream media believes their claims again without extremely compelling evidence. Their index, from what I can see, is smaller than any of the major engines and their relevancy is consistently dismal. I feel really bad for them, personally, as I had incredibly high hopes that someone could challenge Google and make search a more interesting marketplace. Oh well... Maybe next time (assuming VCs are willing to keep throwing 30+ million at the problem).
Methodology: For each of the inputs, I've run a number of searches, spread across different types of query strings. This is an area where understanding how search engine query demand works is vital to judging an engine's performance. Some engines are excellent at returning great results for the most popular queries their users run, but provide very little value in the "tail" of the demand curve. To be a great engine, you must be able to answer both.
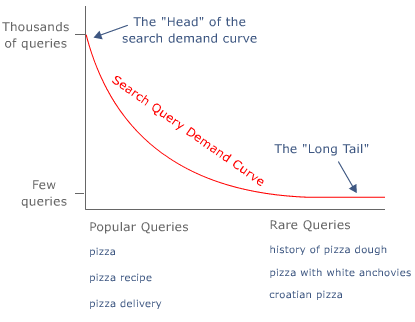
In most instances, I've used search terms and phrases that mark different points along the query-demand scale, from the very popular search queries (like "Barack Obama" and "Photography") to long-tail query strings like ("pacific islands polytheistic cultures" and "chemical compounds formed with baking soda") and everything in between. You can see a full list of the queries I've used below each section. During the testing, I used the following scale to rate the engines' quality:
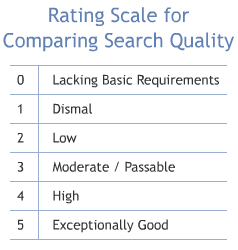
Now let's dive into the lengthy data collection process...
Relevancy
--------------------
Relevancy is defined by the core quality of the results - the more on-topic and valuable they are in fulfilling the searcher's goals and expectations, the higher the relevancy. Measuring quality is always subjective but, in my experience, even a small number of queries provides insight into the relative value of the engine's results. To collect relevancy, I simply judged the degree to which the top results resolved my inquiry, and weighted those that provided the best answers in the first few positions higher than those that had better results further down.
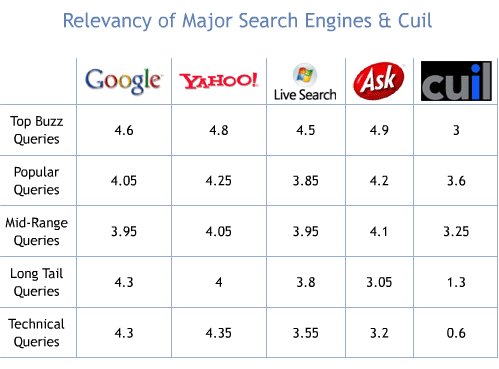
The following are the queries I used to judge each of the engines on performance:
- Top Buzz: gas prices, iphone, facebook, dark knight, barack obama
- Popular: laptops, photography, rental cars, scholarship, house plans
- Mid-Range: fire prevention, calendar software, snow tires, economic stimulus payment, nintendo wii games
- Long Tail: pacific islands polytheistic cultures, chemical compounds formed with baking soda, genuine buddy 50 scooter reviews, google toolbar pagerank formula, getting a novel published
- Technical: metalworking inurl:blog, cricket -site:.co.uk -site:.com.au, dark crystal site:imdb.com, top * ways, definition sycophant
Coverage
--------------------
Coverage points towards a search engine's index size and crawl speed - the bigger the index and faster the engine crawls, the more pages it can return that have relevance to each query. To judge this metric, I focused on the coverage of individual sites (both large and small) as well as queries in the tail of the demand curve.
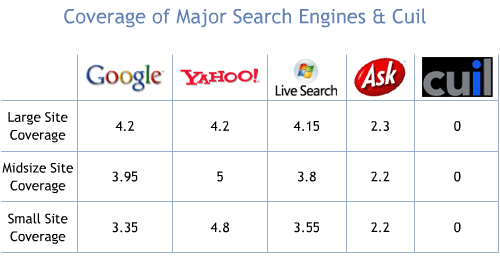
Queries used for evaluation:
- Large Sites: site:government.hp.com, site:research.ibm.com/leem, welsh rugby site:bbc.co.uk, search engine optimization site:w3.org, tango tapas seattle site:nytimes.com
- Mid-Size Sites: site:seomoz.org/blog, site:news.ycombinator.com, site:education.com/magazine, bumbershoot site:thestranger.com, snowboards site:evogear.com
- Small Sites: site:downtownartwalk.com, site:amphl.org/, site:totebo.com, dockboard site:loadingdocksupply.com, site:microsites.audi.com/audia5/
Freshness
--------------------
Although coverage can help to indicate crawl speed and depth, freshness in results shows a keen effort by the engine to place relevant, valuable news items and other trending topics atop the results. I used a number of queries related to recent events both popular and long tail (including new pages from relatively small domains) to test the quality of freshness offered by the engine's index.
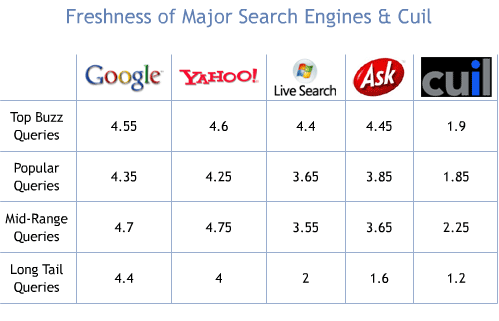
Queries used for evaluation:
- Top Buzz: los angeles earthquake, obama germany, gas prices, ted stevens, beijing olympics
- Popular Queries: new york city weather, dow jones average, seattle mariners schedule, cuil launch, nasa news
- Mid-Range Queries: warp speed engine, unesco world heritage, movie times 98115, comic con 2008, most charitable us cities
- Long Tail Queries: melinda van wingen, over the hedge comic 7/28, seomoz give it up blog, scrabulous facebook, internet startups that failed miserably
Diversity
--------------------
When search queries become ambiguous, lesser engines often struggle to provide high quality results, while those on the cutting edge can serve up much higher value by providing diversity in their results or even active suggestions about the query intent.
.gif)
Queries used for evaluation (I've only used 3 queries per level here, as more ambiguous query strings are very challenging to identify):
- Highly Ambiguous: mouse, ruby, drivers
- Moderate Ambiguity: comics, shipping, earth
- Relative Clarity: ibm, harry potter, graphic design
- Obvious Intent: seattle children's hospital map, color wheel diagram, great gatsby amazon
User Experience
--------------------
The design, interface, features, speed and inclusion of vertical results all play into the user experience. An engine that offers a unique display may rank well or poorly here, depending on the quality of the results delivered and whether the additional data provides real value. Rather than separate queries, I've judged each of the engines based on their offerings in this field (using both the data from the previous sets and my own past knowledge & experience).
.gif)
User experience was based on each of the following:
- Query Speed - the average time from hitting the search button to having a fully-loaded results page
- Results Layout - including the organization of results, ads, query options, search bar, navigation, etc.
- Vertical Inclusion - the inclusion of valuable vertical or "instant answer" style results where useful
- Query Assistance - the use of disambiguation, expansion, and similar/related queries
- Advanced Features - the ability to conduct site specific searches, search for terms only in specific URLs or titles, and narrow by website type, a given folder on a domain, etc.
For those who'd like to provide their own input about how to judge a search engine, Slate.com is running a reader contest to ask How do we know if a new search engine is any good? - I'd strongly encourage participation, as I know the audience here can contribute some excellent insight :-)
If you're interested, here's a screenshot of the Google Docs spreadsheet I created to conduct this research (and I've published the doc online here):
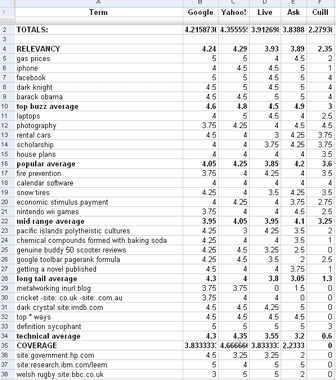
This kind of thing is a lot of work, and although this isn't scientifically or statistically significant, and clearly biased (as I'm the only one who did the judging), I think the results are actually fairly useful and accurate, though it would be fascinating to run public studies like this on a defensible sample size.
p.s. Want to use any of the images or content from this post? Go for it - just please provide a link back :-)



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.