

Google Places SEO: Lessons Learned from Rank Correlation Data
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
In early June of this year, SEOmoz released some ranking correlation data about Google's web results and how they mapped against specific metrics. This exciting work gave us valuable insight into Google's rankings system and both confirmed many assumptions as well as opened up new lines of questions. When Google announced their new Places Results at the end of October, we couldn't help but want to learn more.
In November, we gathered data for 220 search queries - 20 US cities and 11 business "types" (different kinds of queries). This dataset is smaller than our web results, and was intended to be an initial data gathering project before we dove deeper, but our findings proved surprising significant (from a statistical standpoint) and thus, we're making the results and report publicly available.
As with our previous collection and analysis of this type of data, it's important to keep a few things in mind:
- Correlation ≠ Causation - the findings here are merely indicative of what high ranking results are doing that lower ranking results aren't (or, at least, are doing less of). It's not necessarily the case that any of these factors are the cause of the higher rankings, they could merely be a side effect of pages that perform better. Nevertheless, it's always interesting to know what higher ranking sites/pages are doing that they're lower ranking peers aren't.
- Statistical Signifigance - the report specifically highlights results that are more than two standard errors away from statistical significance (98%+ chance of non-zero correlation). Many of the factors we measured fall into this category, which is why we're sharing despite the smaller dataset. In terms of the correlation numbers, remember that 0.00 is no correlation and 1.0 is perfect correlation. It's in our opinion that in algorithms like Google's, where hundreds of factors are supposedly at play together, data in the 0.05-0.1 range is interesting and data in the 0.1-0.3 range potentialy worth more significant attention.
- Ranked Correlations - the correlations are comparing pages that ranked higher vs. those that ranked lower, and the datasets in the report and below are reporting on average correlations across the entire dataset (except where specified), with standard error as a metric for accuracy.
- Common Sense is Essential - you'll see some datapoints, just like in our web results set, that would suggest that sites not following the commonly held "best practices" (like using the name of the queried city in your URL) results in better rankings. We strongly urge readers to use this data as a guideline, but not a rule (for example, it could be that many results using the city name in the URL are national chains with multiple "city" pages, and thus aren't as "local" in Google's eyes as their peers).
With those out of the way, let's dive into the dataset, which you can download a full version of here:
- The 20 cities included:
- Indianapolis
- Austin
- Seattle
- Portland
- Baltimore
- Boston
- Memphis
- Denver
- Nashville
- Milwaukee
- Las Vegas
- Louisville
- Albuquerque
- Tucson
- Atlanta
- Fresno
- Sacramento
- Omaha
- Miami
- Cleveland
- The 11 Business Types / Queries included:
- Restaurants
- Car Wash
- Attorneys
- Yoga Studio
- Book Stores
- Parks
- Ice Cream
- Gyms
- Dry Cleaners
- Hospitals
Interestingly, the results we gathered seem to indicate that across multiple cities, the Google Places ranking algorithm doesn't differ much, but when business/query types are considered, there's indications that Google may indeed be changing up how the rankings are calculated (an alternative explanation is that different business segments simply have dramatically different weights on the factors depending on their type).
For this round of correlation analysis, we contracted Dr. Matthew Peters (who holds a PhD in Applied Math from Univ. of WA) to create a report of his findings based on the data. In discussing the role that cities/query types played, he noted:
City is not a significant source of variation for any of the variables, suggesting that Google’s algorithm is the same for all cities. However, for 9 of the 24 variables we can reject the null hypothesis that business type is a not significant source of variation in the correlation coefficients at a=0.05. This is highly unlikely to have occurred by chance. Unfortunately there is a caveat to this result. The results from ANOVA assume the residuals to be normally distributed, but in most cases the residuals are not normal as tested with a Shapiro-Wilk test.
You can download his full report here.
Next, let's look at some of the more interesting statistical findings Matt discovered. These are split into 4 unique sections, and we're looking only at the correlations with Places results (though the data and report also include web results).
Correlation with Page-Specific Link Popularity Factors
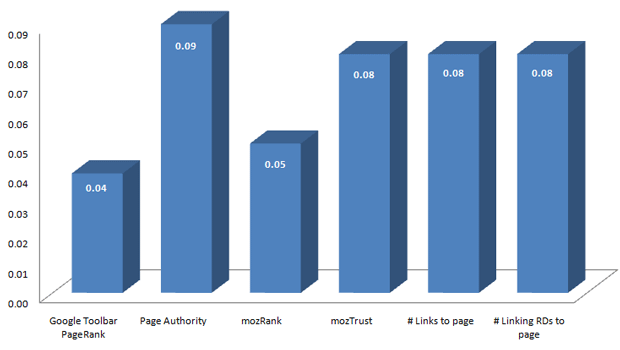
With the exception of PageRank, all data comes via SEOmoz's Linkscape data API.
NOTE: In this data, mozRank and PageRank are not significantly different than zero.
Domain-Wide Link Popularity Factors
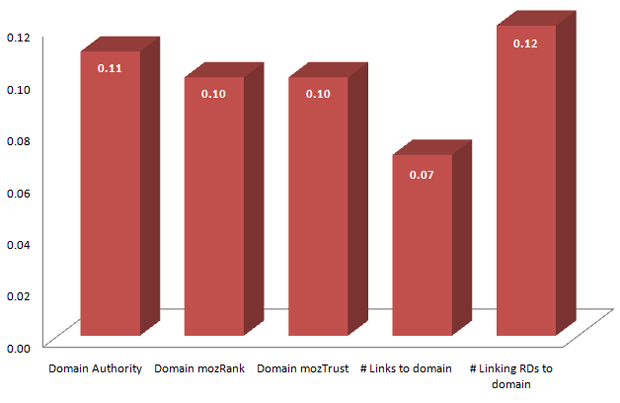
All data comes via SEOmoz's Linkscape data API.
NOTE: In this data, all of the metrics are significant.
Keyword Usage Factors
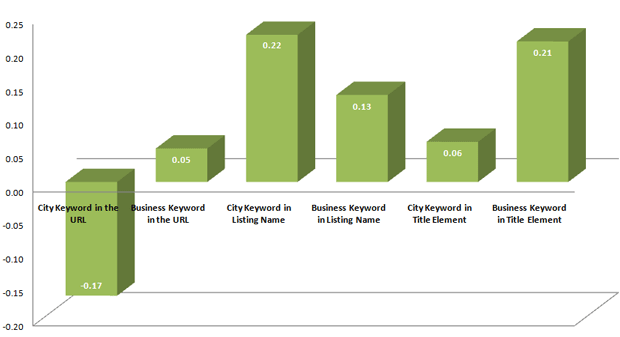
All data comes directly from the results page URL or the Places page/listing. Business keyword refers to the type, such as "ice cream" or "hospital" while city keyword refers to the location, such as "Austin" or "Portland." The relatively large, negative correlation with the city keyword in URLs is an outlier (as no other element we measured for local listings had a significant negative correlation). My personal guess is nationwide sites trying to rank individually on city-targeted pages don't perform as well as local-only results in general and this could cause that biasing, but we don't have evidence to prove that theory and other explanations are certainly possible.
NOTE: In this data, correlations for business keyword in the URL and city keyword in the title element were not significantly different than zero.
Places Listings, Ratings + Reviews Factors
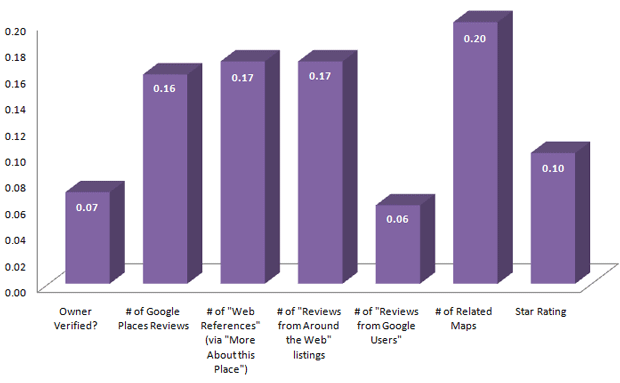
All data comes directly from Google Places' page about the result.
NOTE: In this data, all of the metrics are significant.
Interest Takeaways and Notes from this Research:
- In Places results, domain-wide link popularity factors seem more important than page-specific ones. We've heard that links aren't as important in local/places and the data certainly suggest that's accurate (see the full report to compare correlations), but they may not be completely useless, particularly on the domain level.
- Using the city and business type keyword in the page title and the listing name (when claiming/editing your business's name in the results) may give a positive boost. Results using these keywords seem to frequently outrank their peers. For example:
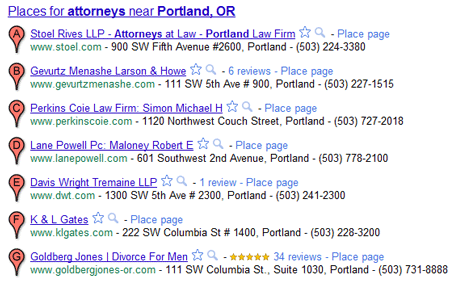
- More is almost always better when it comes to everything associated with your Places listing - more related maps, more reviews, more "about this place" results, etc. However, this metric doesn't appear as powerful as we'd initially thought. It could be that the missing "consistency" metric is a big part of why the correlations here weren't higher.
- Several things we didn't measure in this report are particularly interesting and it's sad we missed them. These include:
- Proximity to centroid (just tough to gather for every result at scale)
- Consistency of listings (supposedly a central piece of the Local rankings puzzle) in address, phone number, business name, type
- Presence of specific listing sources (like those shown on GetListed.org for example)
- This data isn't far out of whack with the perception/opinions of Local SEOs, which we take to be a good sign, both for the data, and the SEOs surveyed :-)
Our hope is to do this experiment again with more data and possibly more metrics in the future. Your suggestions are, of course, very welcome.
As always, we invite you to download the report and raw data and give us any feedback or feel free to do your own analyses and come to your own conclusions. It could even be valuable to use this same process for results you (or your clients) care about and find the missing ingredients between you and the competition.
p.s. Special thanks to Paris Childress and Evgeni Yordanov for help in the data collection process.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.