Unsolved Rogerbot blocked by cloudflare and not display full user agent string.
-
Hi,
We're trying to get MOZ to crawl our site, but when we Create Your Campaign we get the error:
Ooops. Our crawlers are unable to access that URL - please check to make sure it is correct. If the issue persists, check out this article for further help.robot.txt is fine and we actually see cloudflare is blocking it with block fight mode. We've added in some rules to allow rogerbot but these seem to be getting ignored. If we use a robot.txt test tool (https://technicalseo.com/tools/robots-txt/) with rogerbot as the user agent this get through fine and we can see our rule has allowed it.
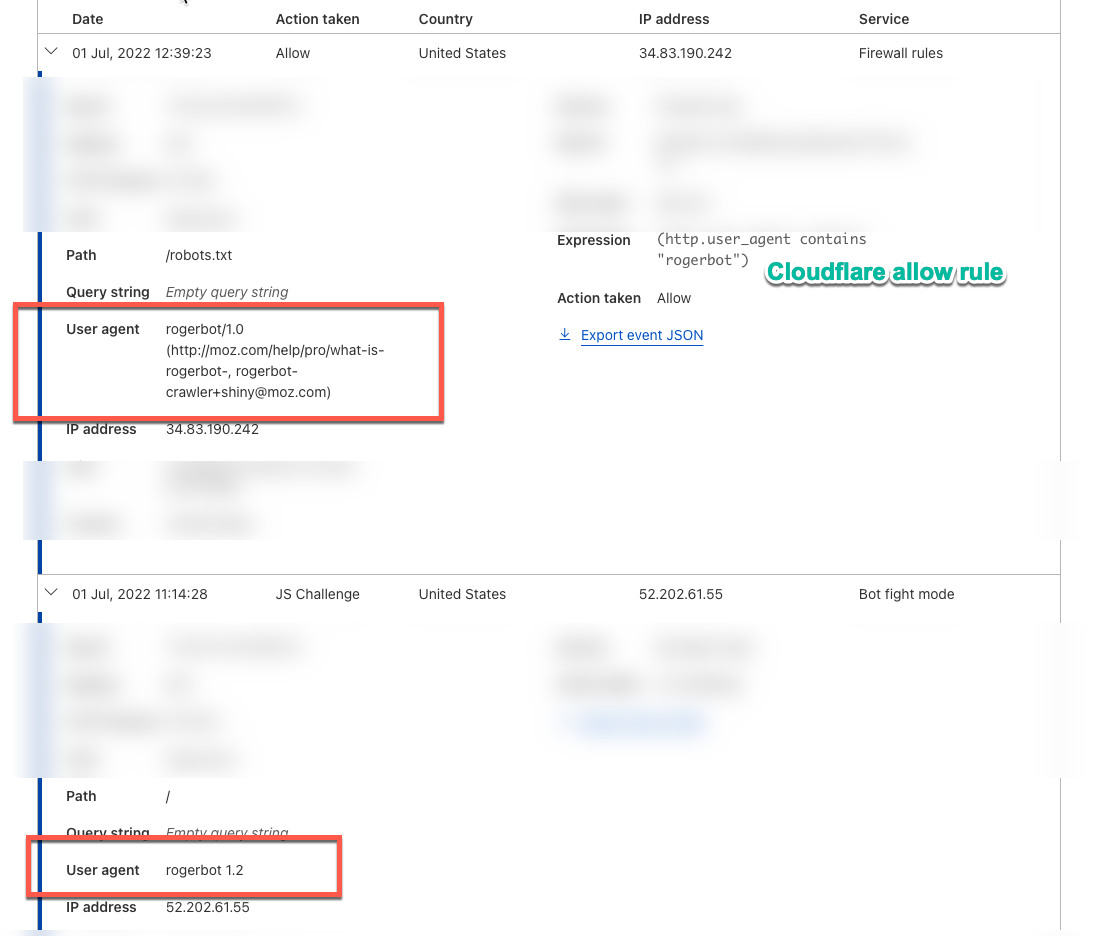
When viewing the cloudflare activity log (attached) it seems the Create Your Campaign is trying to crawl the site with the user agent as simply set as rogerbot 1.2 but the robot.txt testing tool uses the full user agent string rogerbot/1.0 (http://moz.com/help/pro/what-is-rogerbot-, [email protected]) albeit it's version 1.0. So seems as if cloudflare doesn't like the simple user agent. So is it correct the when MOZ is trying to crawl the site it uses the simple string of just rogerbot 1.2 now ?
Thanks
BenCloudflare activity log, showing differences in user agent strings
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved Crawling only the Home of my website
Hello,
Product Support | | Azurius
I don't understand why MOZ crawl only the homepage of our webiste https://www.modelos-de-curriculum.com We add the website correctly, and we asked for crawling all the pages. But the tool find only the homepage. Why? We are testing the tool before to suscribe. But we need to be sure that the tool is working for our website. If you can please help us.0 -

How get rid of 403 crawl error?
My wordpress website has 162 crawl 403 errors. Based on what I read it means that the server is denying crawlers to access the pages. The pages itself will load so guessing it's just an issue with crawlers only. How do I go about fixing this issue?
On-Page Optimization | | emrekeserr30 -

Unsolved How do I cancel this crawl?
The latest crawl on my site was the 4th Jan with a current crawl 'in progress'. How do i cancel this crawl and start a new one? I've been getting keyword ranking etc but no new issues are coming through. Screenshot 2022-05-31 083642.jpg
Moz Tools | | ClaireU0 -

Unsolved Performance Metrics crawl error
I am getting an error:
Product Support | | bhsiao 0
Crawl Error for mobile & desktop page crawl - The page returned a 4xx; Lighthouse could not analyze this page.
I have Lighthouse whitelisted, is there any other site I need to whitelist? Anything else I need to do in Cloudflare or Datadome to allow this tool to work?1 -

Should I block .ashx files from being indexed ?
I got a crawl issue that 82% of site pages have missing title tags
Moz Pro | | thlonius
All this pages are ashx files (4400 pages).
Should I better removed all this files from google ?0 -

Rogerbot's crawl behaviour vs google spiders and other crawlers - disparate results have me confused.
I'm curious as to how accurately rogerbot replicates google's searchbot I've currently got a site which is reporting over 200 pages of duplicate/titles content in moz tools. The pages in question are all session IDs and have been blocked in the robot.txt (about 3 weeks ago), however the errors are still appearing. I've also crawled the page using screaming frog SEO spider. According to Screaming Frog, the offending pages have been blocked and are not being crawled. Webmaster tools is also reporting no crawl errors. Is there something I'm missing here? Why would I receive such different results. Which one's should I trust? Does rogerbot ignore robot.txt? Any suggestions would be appreciated.
Moz Pro | | KJDMedia0 -

Rogerbot did not crawl my site ! What might be the problem?
When I saw the new crawl for my site I wondered why there are no errors, no warning and 0 notices anymore. Then I saw that only 1 page was crawled. There are no Error Messages or webmasters Tools also did not report anything about crawling problems. What might be the problem? thanks for any tips!
Moz Pro | | inlinear
Holger rogerbot-did-not-crawl.PNG0 -

Rogerbot getting cheeky?
Hi SeoMoz, From time to time my server crashes during Rogerbot's crawling escapades, even though I have a robots.txt file with a crawl-delay 10, now just increased to 20. I looked at the Apache log and noticed Roger hitting me from from 4 different addresses 216.244.72.3, 72.11, 72.12 and 216.176.191.201, and most times whilst on each separate address, it was 10 seconds apart, ALL 4 addresses would hit 4 different pages simultaneously (example 2). At other times, it wasn't respecting robots.txt at all (see example 1 below). I wouldn't call this situation 'respecting the crawl-delay' entry in robots.txt as other question answered here by you have stated. 4 simultaneous page requests within 1 sec from Rogerbot is not what should be happening IMHO. example 1
Moz Pro | | BM7
216.244.72.12 - - [05/Sep/2012:15:54:27 +1000] "GET /store/product-info.php?mypage1.html" 200 77813
216.244.72.12 - - [05/Sep/2012:15:54:27 +1000] "GET /store/product-info.php?mypage2.html HTTP/1.1" 200 74058
216.244.72.12 - - [05/Sep/2012:15:54:28 +1000] "GET /store/product-info.php?mypage3.html HTTP/1.1" 200 69772
216.244.72.12 - - [05/Sep/2012:15:54:37 +1000] "GET /store/product-info.php?mypage4.html HTTP/1.1" 200 82441 example 2
216.244.72.12 - - [05/Sep/2012:15:46:15 +1000] "GET /store/mypage1.html HTTP/1.1" 200 70209
216.244.72.11 - - [05/Sep/2012:15:46:15 +1000] "GET /store/mypage2.html HTTP/1.1" 200 82384
216.244.72.12 - - [05/Sep/2012:15:46:15 +1000] "GET /store/mypage3.html HTTP/1.1" 200 83683
216.244.72.3 - - [05/Sep/2012:15:46:15 +1000] "GET /store/mypage4.html HTTP/1.1" 200 82431
216.244.72.3 - - [05/Sep/2012:15:46:16 +1000] "GET /store/mypage5.html HTTP/1.1" 200 82855
216.176.191.201 - - [05/Sep/2012:15:46:26 +1000] "GET /store/mypage6.html HTTP/1.1" 200 75659 Please advise.1