Unsolved The Moz.com bot is overloading my server
-
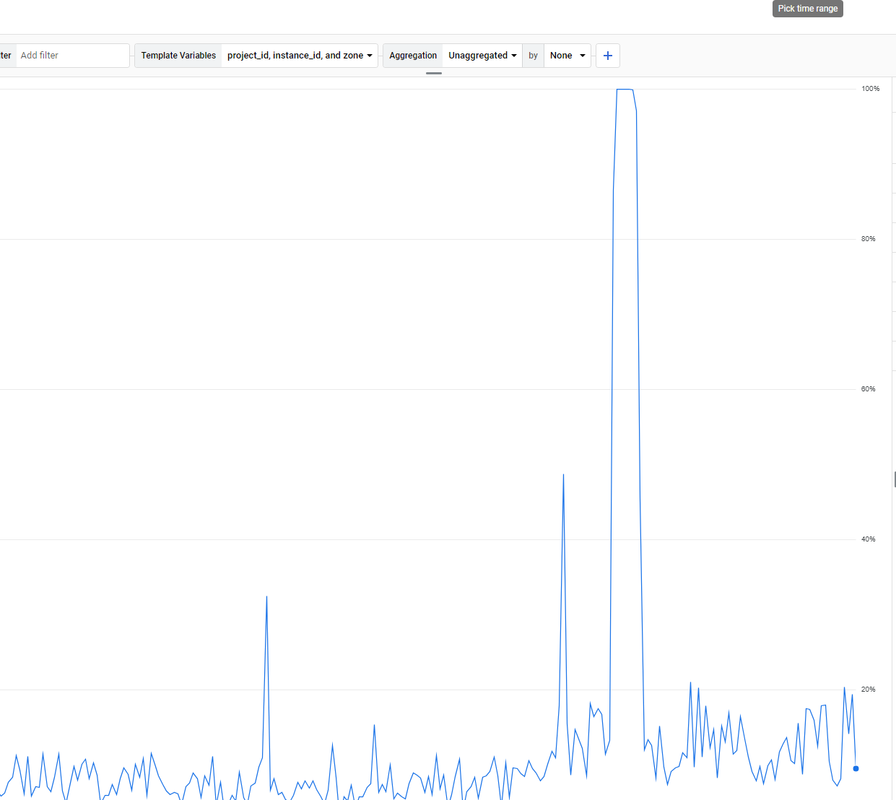 . How to solve it?
. How to solve it? -
maybe crawl delay will help.
-
@paulavervo
Hi,
We do! The best way to chat with us is via our contact form or direct email. We also have chat within Moz Pro.
Please contact us via [email protected] or https://mza.seotoolninja.com/help/contact
We will be happy to help.
Cheers,
Kerry. -
very nice brother i like it very good keep it up !
-
very nice !
-
does the moz team even monitor this forum?
-
If the Moz.com bot is overloading your server, there are several steps you can take to manage and mitigate the issue effectively. First, you can adjust the crawl rate in your
robots.txtfile by specifying a crawl delay for the Moz bot using directives likeUser-agent: rogerbotandUser-agent: dotbot, followed byCrawl-delay: 10to make the bot wait 10 seconds between requests. If this does not suffice, you can temporarily block the bot by disallowing it in yourrobots.txtfile. Additionally, it's a good idea to contact Moz’s support team to explain the issue, as they may offer solutions to adjust the crawl rate for your site. Implementing server-side rate limiting is another effective strategy. For Apache servers, you can add rules in your.htaccessfile to return a 429 Too Many Requests status code to the Moz bots, while for Nginx servers, you can set up rate limiting in your configuration file to control the number of requests per second from a single user or IP address. Monitoring your server’s performance and log files can help identify specific patterns or peak times, allowing you to fine-tune your settings. Furthermore, using a Content Delivery Network (CDN) can help distribute the load by caching content and serving it from multiple locations, reducing the direct impact on your server caused by crawlers. By taking these steps, you can manage the load from the Moz.com bot and maintain your server’s stability and responsiveness.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved 503 Service Unavailable (temporary?) Rogerbot takes a break
A lot of my Moz duties seem to be setting hundreds of issues to ignore because my site was getting crawled while under maintenance. Why can't Rogerbot take a break after running into a few of these and then try again later? Is there an official code for Temporary Service Unavailability that can smart bots pause crawls so that they are not wasting compute, bandwidth, crawl budget and my time?
Product Support | | awilliams_kingston0 -

Unsolved Moz is showing a canonical error that dont belong.
Hi guys, and thanks for this excellent source of information. i have an issue with the moz system because is telling to me that i dont have canonical instructions but i have canonical instructions on all my pages, so... im confused because maybe im not understanding what the system want to show to me. if you can help me i will be very gratefull. here you can see a page that have the canonical instruction. https://drive.google.com/file/d/14U_-Sgu_NQaB7kMBH3AguHQMHyHX9L8X/view?usp=sharing and here you can see what is reporting to me the MOZ system. https://drive.google.com/file/d/1pqgSC-V9WOyBPvQEr06pbqpLf_w7-q8J/view?usp=sharing this is happening on 19 pages, and all the 19 pages have the canonical instruction.
On-Page Optimization | | b-lab
thanks in advance guys.0 -
520 Error from crawl report with Cloudflare
I am getting a lot of 520 Server Error in crawl reports. I see this is related to Cloudflare. We know 520 is Cloudflare so maybe the Moz team can change this from "unknown" to "Cloudflare 520". Perhaps the Moz team can update the "how to fix" section in the reporting, if they have some possible suggestions on how to avoid seeing these in the report of if there is a real issue that needs to be addressed. At this point I don't know. There must be a solution that Moz can provide like a setting in Cloudflare that will permit the Rogerbot if Cloudflare is blocking it because it does not like its behavior or something. It could be that Rogerbot is crawling my site on a bad day or at a time when we were deploying a massive site change. If I know when my site will be down can I pause Rogerbot? I found this https://developers.cloudflare.com/support/troubleshooting/general-troubleshooting/troubleshooting-crawl-errors/
Technical SEO | | awilliams_kingston0 -

Looking for some help to train corporation on MOZ?
Short term. Basically helping a company train internal SEO people from round the globe. Involves time and fee to create your training plus several 4 hour sessions and possible follow up consulting. Pays well. Email me at [email protected]. Thanks Al Blanco
Moz Pro | | InfusionAdmin0 -

Block Moz (or any other robot) from crawling pages with specific URLs
Hello! Moz reports that my site has around 380 duplicate page content. Most of them come from dynamic generated URLs that have some specific parameters. I have sorted this out for Google in webmaster tools (the new Google Search Console) by blocking the pages with these parameters. However, Moz is still reporting the same amount of duplicate content pages and, to stop it, I know I must use robots.txt. The trick is that, I don't want to block every page, but just the pages with specific parameters. I want to do this because among these 380 pages there are some other pages with no parameters (or different parameters) that I need to take care of. Basically, I need to clean this list to be able to use the feature properly in the future. I have read through Moz forums and found a few topics related to this, but there is no clear answer on how to block only pages with specific URLs. Therefore, I have done my research and come up with these lines for robots.txt: User-agent: dotbot
Moz Pro | | Blacktie
Disallow: /*numberOfStars=0 User-agent: rogerbot
Disallow: /*numberOfStars=0 My questions: 1. Are the above lines correct and would block Moz (dotbot and rogerbot) from crawling only pages that have numberOfStars=0 parameter in their URLs, leaving other pages intact? 2. Do I need to have an empty line between the two groups? (I mean between "Disallow: /*numberOfStars=0" and "User-agent: rogerbot")? (or does it even matter?) I think this would help many people as there is no clear answer on how to block crawling only pages with specific URLs. Moreover, this should be valid for any robot out there. Thank you for your help!0 -

Possible Crawling Problem with Screaming Frog and Moz Crawlers
So I'm not sure if what I'm seeing is a problem or not. As of about two weeks ago the Moz crawler has only been able to see www.mysite.com, and none of the links, content, title, ect associated with the page. Essentially the report has one line, what should be the homepage, but it's not able to pull any information from the page but does show a 200 http status code. The report shows nothing blocked by robots or any errors. When I use screaming frog to crawl the site about 75% of the time it just reports one line www.mysite.com with a 200 status code, but again the crawler is not able to actually see the html. The other 25% of the time it works perfectly fine, crawls all pages and sees all meta info and content. There are no errors in Google WMT and everything looks ok there. We have seen a traffic drop the last two weeks but I don't know if this is the reason for it. I can't publicly post the page but if someone has an idea of what might be going on I'd be happy to PM them. Thanks
Moz Pro | | CJ50 -

Links not appearing in Moz tool
Hey Guys I am finding that my Moz tool isn't showing links that are definitely there like from social media etc. Also links that are there about 4-5 months are not showing either! am i doing something wrong?
Moz Pro | | Johnny_AppleSeed0 -

Exact match .ORG/.INFO vs. all query terms .COM - proof?
Hello world 🙂 I have searched among tons of quality articles here on forums, but surprisingly I haven't found topic that goes into the deep water when it comes to a specific KW rich domain problem. Let me first state that I'm mainly based this topic on the information found in following blog posts by randfish (that guru with the beard). http://www.seomoz.org/blog/exact-match-domains-are-far-too-powerful-is-their-time-limited and http://www.seomoz.org/blog/google-vs-bing-correlation-analysis-of-ranking-elements My questions is only related to RANKING aspect of the domains - NOT how is sounds, smell or dance. As all good simple .COM KW domain combinations are already taken, only thing that is left is to be a bit creative using non .COMs exact match, hyphens .COM exact match, all query terms .COM with a letter or word added etc. QUESTION and case study I found a good keyword phrase, let us called it 'super domain' with low competition & high monthly searches and great revenue possibilities. Naturally, first step is to acquire a exact match .COM domain (EMD). But, of course, that is not possible because 'superdomain.com' and super-domain.com has already been taken by some greedy domain broker waiting someone to pay $1.000.000 for it. Not an option. What options do I got? OPT1) superdomainA.COM (keyword phrase with added 'A' at the end) OR OPT2) superdomain.ORG/NET/INFO (keyword phrase on non .COM TLD) I couldn't find any studies with test and clear results regarding this subject. This is VERY important because, regarding to the links I posted, there is a 0.10 better correlation if choosing OPT1) superdomainA.COM, even if using exact match domain OPT2) superdomain.ORG/NET. But they haven't been cross tested in that results in the same post. So it's big '?' sign to me. As SEO market is getting more and more competitive, it is important to not leave anything to chance. I would appreciate if randfish, or anybody else could give some inputs about this. Thanks in advance!
Moz Pro | | RetroOnline0