Schema Markup Doesn't Make Any Sense!! Help Please
-
Hey again Moz community!
I've been trying to read up on schema markup and watch videos multiple times (!) but I can't understand how it works. I would greatly appreciate it if someone can answer these questions:
-
Do I need to ‘markup’ every part of the article? Like “this section can be FAQ snippet, and this can also FAQ etc..". So I guess my question is how detailed does the markup have to be?
-
What are the best tools to use for schema markup for wordpress?
-
What are the best tools to use for schema markup for react web-app?
-
The https://search.google.com/test/rich-results shows if the markup is good for a page, but it doesn’t provide any details. For some articles it says that sitelinks searchbox is detected but that’s only one type of snippet possibility? Do I need to add additional markup for, say, list snippets and FAQ snippets if I want a chance to get those?
Thanks a lot!
Leo W
-
-
Before understanding schemas you need to understand how JSON LD works I had the issue in the past but with a couple of hours studying JSON LD I mean just the basic it will be easier for you
On the other hand, you can use some generators and then modify the code. (Again you will need some basic knowledge of JSON LD)
-
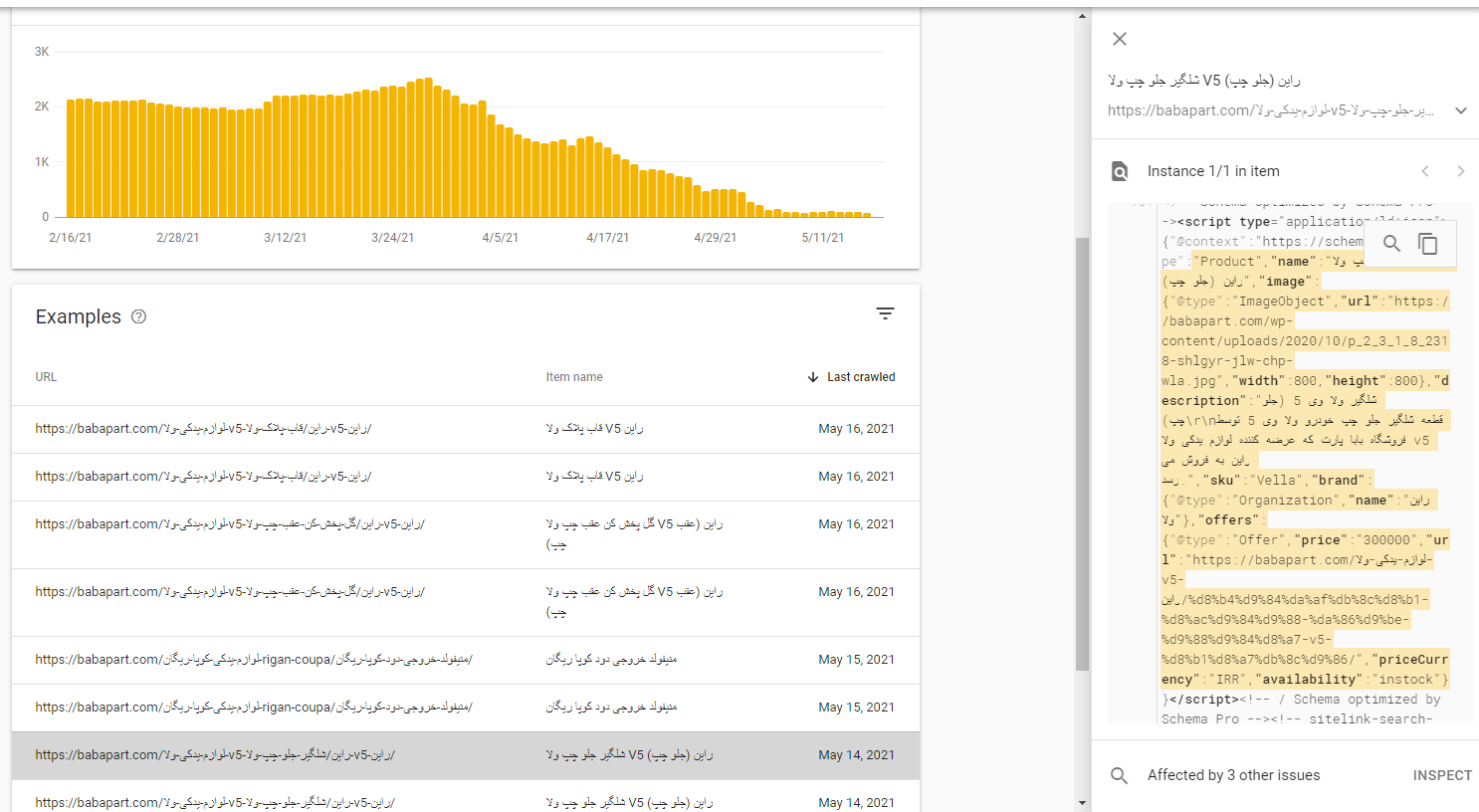
Hi, I have a problem with schema that everything I do will not be solved at all! This is his documentation. Please help me. I am using the Sechma Pro plugin!
my site: https://babapart.com/
document: schema problem.jpg -
Also, it's hard to know if the markup is implemented correctly?
Thanks!
{kind=link}
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

When Mobile and Desktop sites have the same page URLs, how should I handle the 'View Desktop Site' link on a mobile site to ensure a smooth crawl?
We're about to roll out a mobile site. The mobile and desktop URLs are the same. User Agent determines whether you see the desktop or mobile version of the site. At the bottom of the page is a 'View Desktop Site' link that will present the desktop version of the site to mobile user agents when clicked. I'm concerned that when the mobile crawler crawls our site it will crawl both our entire mobile site, then click 'View Desktop Site' and crawl our entire desktop site as well. Since mobile and desktop URLs are the same, the mobile crawler will end up crawling both mobile and desktop versions of each URL. Any tips on what we can do to make sure the mobile crawler either doesn't access the desktop site, or that we can let it know what is the mobile version of the page? We could simply not show the 'View Desktop Site' to the mobile crawler, but I'm interested to hear if others have encountered this issue and have any other recommended ways for handling it. Thanks!
Intermediate & Advanced SEO | | merch_zzounds0 -

My Website Has a Google Penalty, But I Can't Disavow Links
I have a client who has definitely been penalized, rankings dropped for all keywords and hundreds of malicious backlinks when checked with WebMeUp....However, when I run the backlink portfolio on Moz, or any other tool, they don't appear anyone, and all the links are dead when I click on the actual URL. That being said, I can't disavow links that don't exist, and they don't show up in Webmaster Tools, but I KNOW this site has been penalized. Also- I noticed this today (attached). Any suggestions? I've never come across this issue before. xT6JNJC.png
Intermediate & Advanced SEO | | 01023450 -

Incoming links which don't exists...
I believe our site is being penalized/held back in rankings, and I think this is why... We placed an advert on a website which they didn't make "no follow" so we had hundreds of site-wide links coming into our site. We asked them to remove the advert which they did. This was 4 months ago, and the links are still showing in GWMT. We have look into their pages which GWMT is saying still link to us, but these a number pages aren't being indexed by Google, and others aren't being cached. Is it possible that because Google cant find these pages, it can tell our link has been removed? And/or are we being penalized for this? Many thanks
Intermediate & Advanced SEO | | jj34341 -

Need help on SEO for my site. Can't figure out what is wrong.
My site, findyogi.com, isn't ranking well in google SERPs. For some good content and matching keyword, my pages are ranking 200+ whereas other sites that have similar or lower authority are ranking in top 10. I must be doing something fundamentally wrong but can't seem to figure out what. I am not looking at ranking 1 on google right now but my pages don't appear even on page 2-4. Sample Keyword- "Samsung galaxy s4 price in india" . Matching page - www.findyogi.com/mobiles/samsung/samsung-galaxy-s4-b94a37/price Please help.
Intermediate & Advanced SEO | | namansr0 -

Infinite Redirect Loop without trailing slash, please help
I've been searching for an answer all day, I can't seem to figure this out. When I Fetch my blog as Google(http://www.mysite.com/blog) WITHOUT a trailing slash at the end, I get this error: The page seems to redirect to itself. This may result in an infinite redirect loop **HTTP/1.1 301 Moved Permanently** When I Fetch my blog as Google WITH the trailing slash at the end(http://www.mysite.com/blog/), it is fine without errors. When I pull it up in a browser comes up fine both with and without the trailing slash. My .htaccess file in the root directory contains this: RewriteEngine On
Intermediate & Advanced SEO | | debc
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /index.htm\ HTTP/
RewriteRule ^index.htm$ http://www.mysite.com/ [R=301,L]
RewriteCond %{HTTP_HOST} ^mysite.com$
RewriteRule ^(.*)$ http://www.mysite.com/$1 [R=301,L] My .htaccess file in the blog directory contains this: BEGIN WordPress <ifmodule mod_rewrite.c="">RewriteEngine On
RewriteBase /blog/
RewriteCond %{REQUEST_URI} ^./index.php/. [NC]
RewriteRule ^index.php/(.*)$ http://www.mysite.com/blog/$1 [R=301,L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /blog/index.php [L]</ifmodule> END WordPress Do I have something incorrectly coded in these .htaccess files that could be causing this? Or is there something else I should look at? Thank you for any help!!0 -

Schema.org and Testimonials
Does anyone know which fields and code are necessary to embed a testimonial into a page using schema.org?
Intermediate & Advanced SEO | | rarbel0 -

My homepage doesn't rank anymore. It's been replaced by irrelevant subpages which rank around 100-200 instead of top 5.
Hey guys, I think I got some kind of penalty for my homepage. I was in top5 for my keywords. Then a few days ago, my homepage stopped ranking for anything except searching for my domain name in Google. sitename.com/widget-reviews/ previously ranked #3 for "widget reviews"
Intermediate & Advanced SEO | | wearetribe
but now....
sitename.com/widget-training-for-pet-cats/ is ranking #84 for widget reviews instead. Similarly across all my other keywords, irrelevant, wrong pages are ranking. Did I get some kind of penalty?0 -

Robots.txt: Link Juice vs. Crawl Budget vs. Content 'Depth'
I run a quality vertical search engine. About 6 months ago we had a problem with our sitemaps, which resulted in most of our pages getting tossed out of Google's index. As part of the response, we put a bunch of robots.txt restrictions in place in our search results to prevent Google from crawling through pagination links and other parameter based variants of our results (sort order, etc). The idea was to 'preserve crawl budget' in order to speed the rate at which Google could get our millions of pages back in the index by focusing attention/resources on the right pages. The pages are back in the index now (and have been for a while), and the restrictions have stayed in place since that time. But, in doing a little SEOMoz reading this morning, I came to wonder whether that approach may now be harming us... http://www.seomoz.org/blog/restricting-robot-access-for-improved-seo
Intermediate & Advanced SEO | | kurus
http://www.seomoz.org/blog/serious-robotstxt-misuse-high-impact-solutions Specifically, I'm concerned that a) we're blocking the flow of link juice and that b) by preventing Google from crawling the full depth of our search results (i.e. pages >1), we may be making our site wrongfully look 'thin'. With respect to b), we've been hit by Panda and have been implementing plenty of changes to improve engagement, eliminate inadvertently low quality pages, etc, but we have yet to find 'the fix'... Thoughts? Kurus0