Is this correct?
-
I noticed Moz using the following for its homepage
Is this best practice though? The reason I ask is that, I use and I've been reading this page by Google
http://googlewebmastercentral.blogspot.co.uk/2013/04/5-common-mistakes-with-relcanonical.html
5 common mistakes with rel=canonical
Mistake 2: Absolute URLs mistakenly written as relative URLs
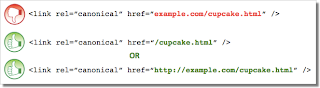
The tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
-
Thanks
-
Ow im sorry, totally mis understood - sorry if i was explaining something you understood.
Moz use
you said they use
/> i presume now you mean the / at the end of the tag.
This is an old school closing tag. HTML elements were traditionally opened and closed in HTML versions before HTML5. Normally this is done obviously with tags such the opener "
" and closer "
". However some elements dont have a seperate closing tag such as "" tags. In older html versions these were closed using the format
Missing these tags didn't used to do much as most browsers rendered the page correctly anyways, but best practice was to include the / to close elements. However with the dawn of HTML5 things changed.
HTML5 doesn't require the closing tag. Elements that used to require one now simply dont. Browsers still understand both versions absolutely fine and its kinda ok to use either. But the most modern and correct practice is to use it without.
Edit:
Racking my brain, i believe the / was added as best practice to assure compatibility with XHTML which was pegged to be the next version of HTML. When XHTML was scrapped in favour of HTML5 it changed. Somebody may correct me on this one though
")
-
Thanks, I realise the usage should be a correct relative URL or a correctly formed absolute URL. In Moz's case, they used a correctly formed absolute URL.
My question is more around...why not use "/"?
Cyto
-
Looks fine to me, i think you misunderstand Mistake 2
They are using an absolute URL
If they did the "mistake 2" their canonical tag would look like
You canonical tags should always be absolute for good practice
is correct
or any variant of this would be wrong

Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

H1 and Schema Codes Set Up Correctly?
Greetings: It was pointed out to me that the h1 tags on my website (www.nyc-officespace-leader.com) all had exactly the same text and that duplication may be contributing to the very low page authority for most URLs. The duplicate h1 appears in line 54-54 (see below) of the home page: www.nyc-officespace-leader.com: itemscope itemtype="http://schema.org/LocalBusiness" style="position:absolute;top:-9999em;"> <span<br>itemprop="name">Metro Manhattan Office Space</span<br> <img< p="">But the above refers to schema" so is this really duplicate H1 or is there an exception if the H1 is within a schema? Also, I was told that the company street address and city and state were set up incorrectly as part of an alt tag. However these items also appear as schema in lines 49-68 shown below: Dangerous for me to perform surgery on the code without being certain about these key items!! Could ask my developer, however they may be uncomfortable considering that they set this up in the 1st place. So the view of neutral professionals would be highly welcome! itemprop="address" itemscope itemtype="http://schema.org/PostalAddress">
Intermediate & Advanced SEO | | Kingalan1
<span<br>itemprop="streetAddress">347 5th Ave #1008
<span<br>itemprop="addressLocality">New York
<span<br>itemprop="addressRegion">NY
<span<br>itemprop="postalCode">10016<div<br>itemprop="brand" itemscope itemtype="http://schema.org/Organization">
---------------------------------------------------------------------------</div<br></span<br></span<br></span<br></span<br></img<>0 -

Robots.txt wildcards - the devs had a disagreement - which is correct?
Hi – the lead website developer was assuming that this wildcard: Disallow: /shirts/?* would block URLs including a ? within this directory, and all the subdirectories of this directory that included a “?” The second developer suggested that this wildcard would only block URLs featuring a ? that come immediately after /shirts/ - for example: /shirts?minprice=10&maxprice=20 BUT argued that this robots.txt directive would not block URLS featuring a ? in sub directories - e.g. /shirts/blue?mprice=100&maxp=20 So which of the developers is correct? Beyond that, I assumed that the ? should feature a * on each side of it – for example - /? - to work as intended above? Am I correct in assuming that?
Intermediate & Advanced SEO | | McTaggart0 -
Is this the correct way of using rel canonical, next and prev for paginated content?
Hello Moz fellows, a while ago (3-4 years ago) we setup our e-commerce website category pages to apply what Google suggested to correctly handle pagination. We added rel "canonicals", rel "next" and "prev" as follows: On page 1: On page 2: On page 3: And so on, until the last page is reached: Do you think everything we have been doing is correct? I have doubts on the way we have handled the canonical tag, so, any help to confirm that is very appreciated! Thank you in advance to everyone.
Intermediate & Advanced SEO | | fablau0 -

The correct hreflang for the GB
Hi does anyone know the correct hreflang for the UK Google webmaster error: International Targeting | Language > 'en-GB' - no return tags (sitemaps)Sitemap provided URLs and alternate URLs in 'en-GB' that do not have return tags.Thanks you all
Intermediate & Advanced SEO | | Taiger0 -
Robots.txt: how to exclude sub-directories correctly?
Hello here, I am trying to figure out the correct way to tell SEs to crawls this: http://www.mysite.com/directory/ But not this: http://www.mysite.com/directory/sub-directory/ or this: http://www.mysite.com/directory/sub-directory2/sub-directory/... But with the fact I have thousands of sub-directories with almost infinite combinations, I can't put the following definitions in a manageable way: disallow: /directory/sub-directory/ disallow: /directory/sub-directory2/ disallow: /directory/sub-directory/sub-directory/ disallow: /directory/sub-directory2/subdirectory/ etc... I would end up having thousands of definitions to disallow all the possible sub-directory combinations. So, is the following way a correct, better and shorter way to define what I want above: allow: /directory/$ disallow: /directory/* Would the above work? Any thoughts are very welcome! Thank you in advance. Best, Fab.
Intermediate & Advanced SEO | | fablau1 -
Incorrect cached page indexing in Google while correct page indexes intermittently
Hi, we are a South African insurance company. We have a page http://www.miway.co.za/midrivestyle which has a 301 redirect to http://www.miway.co.za/car-insurance. Problem is that the former page is ranking in the index rather than the latter. The latter page does index occasionally in the same position, but rarely. This is primarily for search phrases like "car insurance" and "car insurance quotes". The ranking was knocked down the index with Penquin 2.0. It was not ranking at all but we have managed to recover to 12/13. This abnormally has only been occurring since the recovery. The correct page does index for other search terms like "insurance for car". Your help would be appreciated, thanks!
Intermediate & Advanced SEO | | miway0 -

Google Not Indexing Description or correct title (very technical)
Hey guys, I am managing the site: http://www.theattractionforums.com/ If you search the keyword "PUA Forums", it will be in the top 10 results, however the title of the forum will be "PUA Forums" rather than using the code in the title tag, and no description will display at all (despite there being one in the code). Any page other than the home-page that ranks shows the correct title and description. We're completely baffled! Here are some interesting bits and pieces: It shows up fine on Bing If I go into GWT and Fetch as Google Bot, it shows up as "Unreachable" when I try to pull the home-page. We previously found that it was pulling 'index.htm' before 'index.php' - and this was pulling a blank page. I've fixed this in the .htaccess however to make it redirect, however this hasn't solved the problem. I've disallowed it from pulling the description .etc from the Open Directory with the use of meta tags - didn't change anything. It's vBulletin and is running vBSEO Any suggestions at all guys? I'll be forever in anyones debt who can solve this, it's proving to be near impossible to fix. Here is the .htaccess file, it may be a part of the issue: RewriteEngine On DirectoryIndex index.php index.html Redirect /index.html http://www.theattractionforums.com/index.php RewriteCond %{HTTP_HOST} !^www.theattractionforums.com
Intermediate & Advanced SEO | | trx
RewriteRule (.*) http://www.theattractionforums.com/$1 [L,R=301] RewriteRule ^((urllist|sitemap_).*.(xml|txt)(.gz)?)$ vbseo_sitemap/vbseo_getsitemap.php?sitemap=$1 [L] RewriteCond %{REQUEST_URI} !(admincp/|modcp/|cron|vbseo_sitemap/)
RewriteRule ^((archive/)?(..php(/.)?)?)$ vbseo.php [L,QSA] RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_FILENAME} !^(admincp|modcp|clientscript|cpstyles|images)/
RewriteRule ^(.+)$ vbseo.php [L,QSA]
RewriteRule ^forum/(.*)$ http://www.theattractionforums.com/$1 [R=301,L]0 -

Getting Google to Correct a Misspelled Site Link...Help!
My company website recently got its site links in google search... WooHoo! However, when you type TECHeGO into Google Search one of the links is spelled incorrectly. Instead of 'CONversion Optimization' its 'COversion Optimization'. At first I thought there was a misspelling on that page somewhere but there is not and have come to the conclusion that Google has made a mistake. I know that I can block the page in webmaster tools (No Thanks) but how in the crap can I get them to correct the spelling when no one really knows how to get them to appear in the first place? Riddle Me That Folks! sitelink.jpg
Intermediate & Advanced SEO | | TECHeGO0