Strange Crawl Report
-
Hey Moz Squad,
So I have kind of strange case. My website locksmithplusinc.com has been around for a couple years. I have had all sorts of pages and blogs that have maybe ranked for a certain location a longtime ago and got deleted so I could speed up the site and consolidate my efforts. I said that because I think that might be part of the problem.
When I was crawl reporting my site just three weeks ago on moz I had over 23 crawl report issues. Duplicate pages, missing meta tags the regular stuff. But now all of a sudden when I crawl report on MOZ it comes up with Zero issues. So I did another crawl On google analytic and this is what came up.
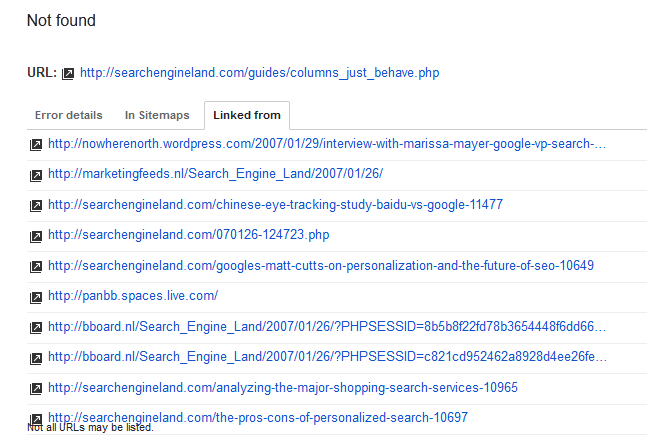
SO im very confused because none of these url's are even url's on my site. So maybe people are searching for this stuff and clicking on broken links that are still indexed and getting this 404 error?
What do you guys think?
Thank you guys so much for taking a shot at this one.
-
The team from Giovatto is correct, you can click on the url and see where it is being linked from.
-
These are "Not Found" errors, meaning they are pages that do not exist but are being linked to somewhere on your site or another site.
If the page that is not found is a relevant page that holds a prominent ranking position, then by all means you probably want to either fix the broken link that was found or 301 redirect this broken URL to the correct URL.
You can check what page is linking to this broken URL by clicking the URL in the error report and switching to the "Linked From" tab and then decide if it's something that needs to be fixed.
{kind=link}
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Client suffered a malware attack. Removed links not being crawled by Google!
Hi all, My client suffered a malware attack a few weeks ago where an external site somehow created 700 plus links on my clients site with their content. I removed all of the content and redirected the pages to the home page. I then created a new temporary xml sitemap with those 700 links and submitted the sitemap to Google 9 days ago. Google has crawled the sitemap a few times but not the individual links. When I click on the crawl report for the sitemap in GSC, I see that the individual links still have the last crawled date from before they were removed. So in Googles eyes, that old malicioud content still exists. What do I do to ensure Google knows the contnt is gone and redirected? Thanks!
Technical SEO | | sk19900 -

Crawl Issues / Partial Fetch Via Google
We recently launched a new site that doesn't have any ads, but in Webmaster Tools under "Fetch as Google" under the rendering of the page I see: Googlebot couldn't get all resources for this page. Here's a list: URL Type Reason Severity https://static.doubleclick.net/instream/ad_status.js
Technical SEO | | vikasnwu Script
Blocked
Low
robots.txt
https://googleads.g.doubleclick.net/pagead/id
AJAX
Blocked
Low
robots.txt
Not sure where that would be coming from as we don't have any ads running on our site?
Also, it's stating the the fetch is a "partial" fetch.
Any insight is appreciated.
0
Script
Blocked
Low
robots.txt
https://googleads.g.doubleclick.net/pagead/id
AJAX
Blocked
Low
robots.txt
Not sure where that would be coming from as we don't have any ads running on our site?
Also, it's stating the the fetch is a "partial" fetch.
Any insight is appreciated.
0 -

Crawl Diagnostics: Duplicate Content Issues
The Moz crawl diagnostic is showing that I have some duplicate content issues on my site. For the most part, these are variations of the same product that are listed individually (i.e size/color). What would be the best way to deal with this? Choose one variation of the product and add a canonical tag? Thanks
Technical SEO | | inhouseseo0 -

New Page Showing Up On My Reports w/o Page Title, Words, etc - However, I didn't create it
I have a WordPress site and I was doing a crawl for errors and it is now showing up as of today that this page : https://thinkbiglearnsmart.com/event-registration/?event_id=551&name_of_event=HTML5 CSS3 is new and has no page title, words, etc. I am not even sure where this page or URL came from. I was messing with the robots.txt file to allow some /category/ posts that were being hidden, but I didn't re-allow anything with the above appendages. I just want to make sure that I didn't screw something up that is now going to impact my rankings - this was just a really odd message to come up as I didn't create this page recently - and that shouldnt even be a page accessible to the public. When I edit the page - it is using an Event Espresso (WordPress plugin) shortcode - and I don't want to noindex this page as it is all of my events. Sorry this post is confusing, any help or insight would be appreciated! I am also interested in hiring someone for some hourly consulting work on SEO type issues if anyone has any references. Thank you!
Technical SEO | | webbmason0 -

Moz Crawl Reporting Duplicate content on "template" styled pages
We have a lot of detail pages on our site that reference specific scholarships. Each page has a different Title and Description. They also have unique information all regarding the same data points. The pages are displayed in a similar structure to the user so the data is easy to read. My problem is a lot of these pages are being reported as duplicate content when they certainly are not. Most of them are reported as duplicates when they have the same sponsor. They may have the same contact information listed. These two are being reported as duplicate of each other. They share some data but they are definitely different scholarships. http://www.collegexpress.com/scholarships/adelaide-mcclelland-garden-club-scholarship/9254/ http://www.collegexpress.com/scholarships/mary-wannamaker-witt-and-lee-hampton-witt-memorial-scholarship/10785/ Would it help to add a Canonical for each page to themselves? Any other suggestions would be great. Thanks
Technical SEO | | GeorgeLaRochelle0 -

Crawling and indexing content
If a page element (div, e.g.) is initially hidden and shown only by a hover descriptor or Javascript call, will Google crawl and index it’s content?
Technical SEO | | Mont0 -

How far into a page will a spider crawl to look for text?
How far into a page will a spider crawl to look for text? I've heard a spider will only crawl the first 3kb, but can't find an authoritative source for that information.
Technical SEO | | crvw0